
 Я месяцами сжигал токены, рассказывает Робин ван ден Хёвел
Я месяцами сжигал токены, рассказывает Робин ван ден Хёвел
 102
102
Я месяцами сжигал токены, рассказывает Робин ван ден Хёвел.
Даже не подозревал об этом.
Математика:
1 страница PDF = 3,000 токенов 1 скриншот ≈ 1,300 токенов 1 файл markdown = меньше 100
3 правила, которые я усвоил (первое — элементарное):
→ Конвертирую PDF в markdown перед загрузкой
→ Держу файлы "о себе" в пределах 2,000 слов
→ Не скидываю целые папки; выбираю файлы точечно, когда это возможно
Осознание ударило жестко.
Я относился к токенам так, будто они бесплатные 🤣
Это не так.
Каждый слитый токен = медленные ответы, быстрая пробивка лимитов, высокие счета.
Не нужно быть технарем, чтобы это пофиксить.
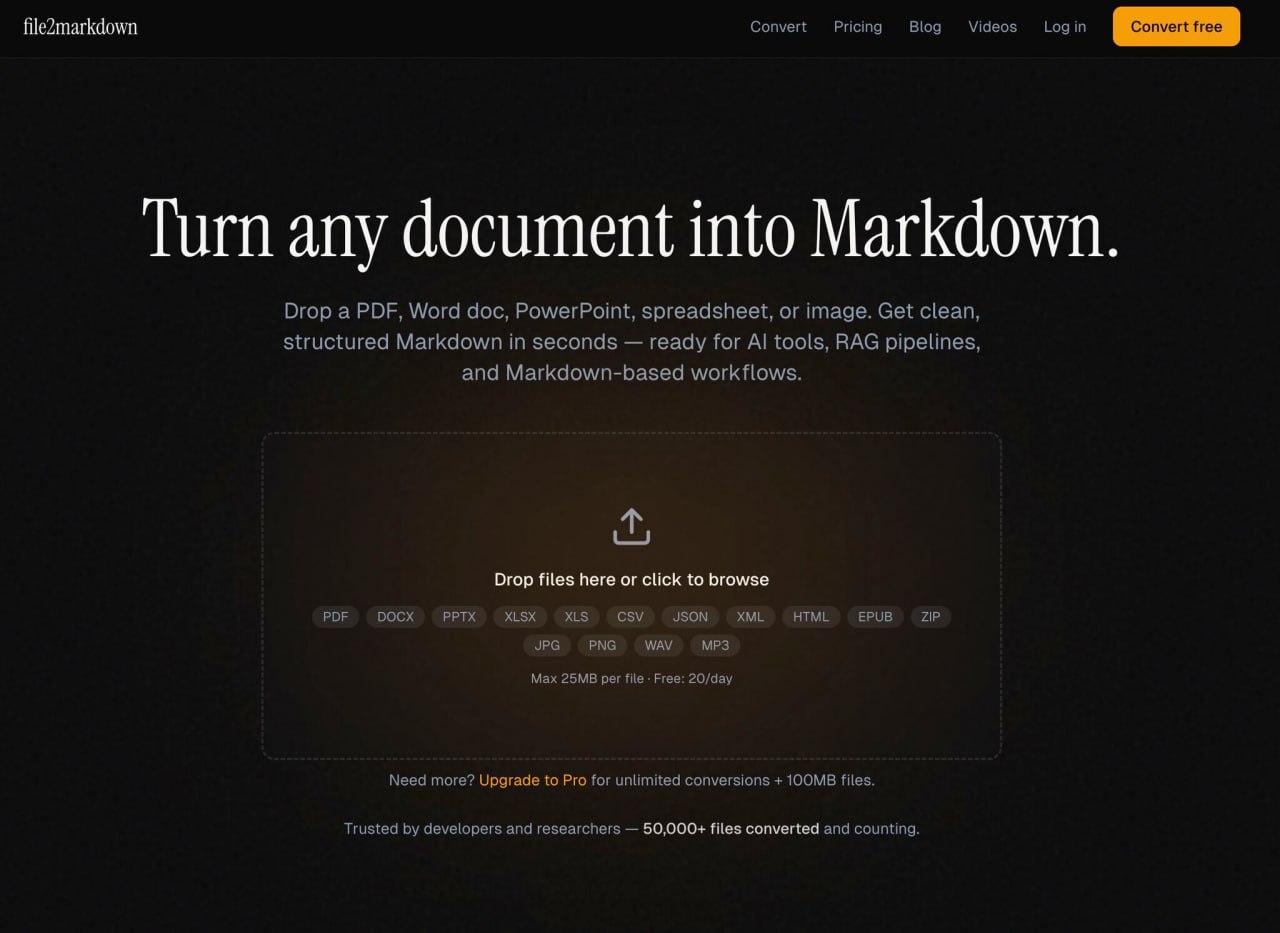
Мой любимый инструмент: file2markdown.ai
Закинул → сконвертировал → загрузил в чат с LLM.
Лучшие юзеры AI не промпты пишут лучше.
Они лучше готовят данные.
Инсайты SEO-комьюнити
— Ценовые модели LLM сейчас субсидируются; по мере перехода компаний на прайсинг от себестоимости, эффективность токенов становится критически важной операционной метрикой, превращая препроцессинг в markdown из опциональной фичи в базовую необходимость.
— Экономия токенов при конвертации из PDF в markdown частично нивелируется чисткой мусора (лишние пробелы, артефакты парсинга PDF) — дельта по токенам сужается, когда препроцессинг нормализует оба формата, хотя markdown всё равно выигрывает.
— Оптимизация формата на экспорт зеркалит эффективность на входе — выгрузка в markdown вместо тяжелых документов (Word, HTML) напрямую режет потребление токенов, распространяя этот принцип на весь рабочий цикл.
@MikeBlazerX
⚠️ Закрытый канал: @MikeBlazerPRO
– https://www.linkedin.com/posts/robinmarketing_ive-...
– https://t.me/MikeBlazerX
– https://t.me/tribute/app?startapp=sE4X
Источник новости https://t.me/mikeblazerx/6387...
ТОП-10 каналов по SEO ![]()
Последние интересные посты
