
 "Обнаружено - в настоящее время не проиндексировано"...
"Обнаружено - в настоящее время не проиндексировано"...
 230
230
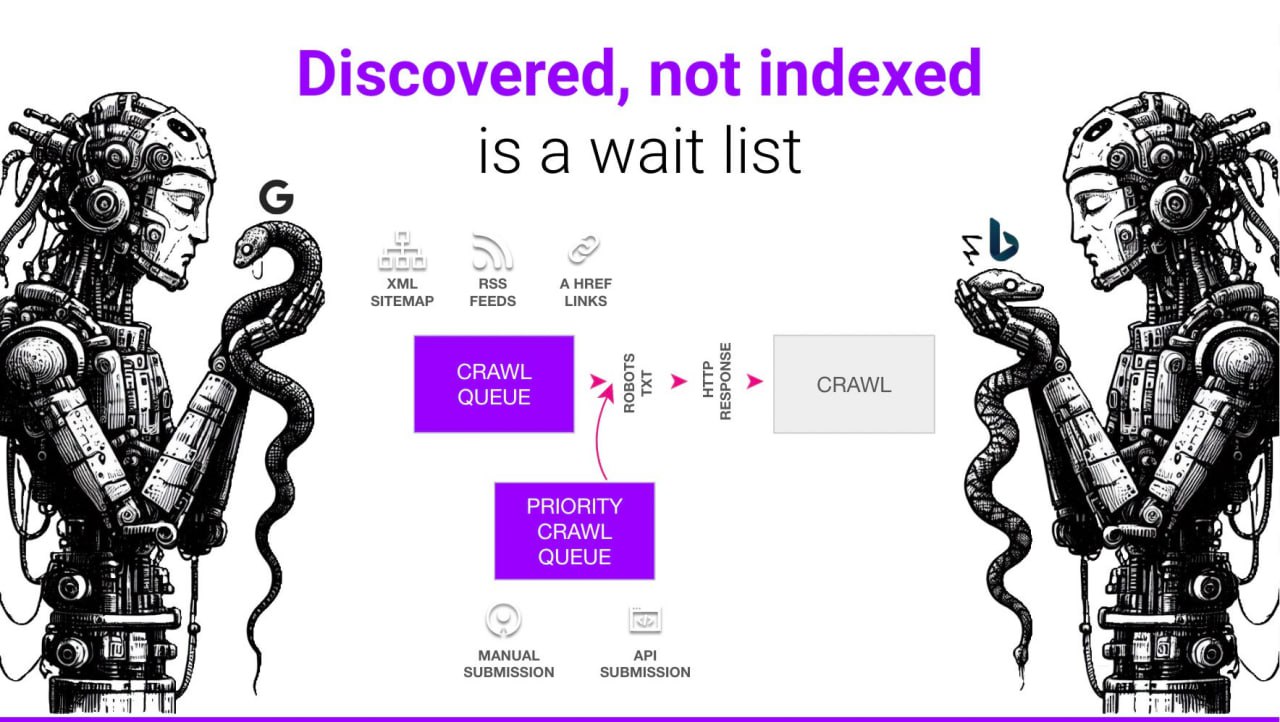
"Обнаружено - в настоящее время не проиндексировано" - это список ожидания
Что на самом деле означает "Discovered - currently not indexed"?
У Гуглбота и Бингбота всегда есть очередь URL-адресов, ожидающих краулинга.
Она формируется из URL, найденных в:
📍 XML-сайтмапах
📍 RSS-фидах
📍 Во внутренних и внешних ссылках
Краулинг работает как двухуровневая система с приоритетной очередью, которая позволяет ускорить процесс, когда вы:
📍 Вручную отправляете URL в GSC или Bing Webmaster Tools
📍 Отправляете через API индексации
Все эти URL, ожидающие в очередях, помечены как "Discovered - currently not indexed".
Поисковики знают об их существовании, но еще не добрались до их краулинга.
Большое количество таких исключений показывает, что нужно сфокусироваться на оптимизации краулинга.
-
Перейдем к "Crawled - currently not indexed" (Просканировано - в настоящее время не проиндексировано).
Многие считают, что это проблема качества контента.
Но часто это не так.
Это техническая проблема.
Либо вы прячете большую часть SEO-значимого контента за JavaScript.
В этом случае решение простое - прекратите это делать.
Особенно учитывая растущие доказательства того, что AI-краулеры не могут получить доступ к контенту с клиентским рендерингом.
Либо исключение происходит потому, что контент все еще анализируется для понимания контекста:
📍 Мета-теги, каноникалы, структурированные данные, текст, изображения, видео - все требует оценки.
📍 Нужно отметить дубликаты, оценить качество и проверить информационную ценность.
📍 Необходимо учесть авторитет бренда, силу путей и ссылочные сигналы.
И все это требует времени.
Чтобы ускорить процесс и уменьшить количество ценных URL, помеченных как "Crawled - currently not indexed", сосредоточьтесь на оптимизации краулинга и индексации.
@MikeBlazerX
– https://www.linkedin.com/feed/update/urn:li:activi...
– https://www.linkedin.com/feed/update/urn:li:activi...
– https://t.me/MikeBlazerX
Источник новости https://t.me/mikeblazerx/4624...
ТОП-10 каналов по SEO ![]()
Последние интересные посты
