
 LLM-модели вырезают бренды из ответов: данные раскрывают разрыв...
LLM-модели вырезают бренды из ответов: данные раскрывают разрыв...
 100
100
LLM-модели вырезают бренды из ответов: данные раскрывают разрыв в логике цитирования
Анализ 541,213 ответов LLM по 20 брендам и 6 ИИ-платформам раскрывает структурную дыру в логике рекомендаций: алгоритм цитирует контент, но игнорирует бренды.
Твой домен проходит порог извлечения.
Имя конкурента выживает при выборе бренда.
Данные железобетонно подтверждают post-hoc модель: LLM сначала генерируют ответ — вытягивая названия брендов из параметрической памяти, — а затем ищут источники для подкрепления этого выбора.
Цитации здесь выступают библиографией, а не исходным брейнштормом.
Когда бренд упоминается в ответе ИИ, частота его цитирования взлетает до 53.1%.
Когда НЕ упоминается, цифра падает до 10.6% — перевернутая разница в 5 раз.
Если бы рекомендации строились на базе поиска источников, эти метрики были бы сопоставимы.
Они не сопоставимы.
Seer прогнали тесты на 362,188 ответах LLM.
Механика: покупатель спрашивает "лучшие решения для [категория]"?
→ LLM достает имена конкурентов из памяти обучения → алгоритм поиска находит твой релевантный контент → твой урл прикручивается как источник-подтверждение → конкуренты получают прямую рекомендацию, твой бренд остается за бортом.
Честная оговорка: без логов генерации токенов это мощное поведенческое доказательство, а не стопроцентно подтвержденная архитектура.
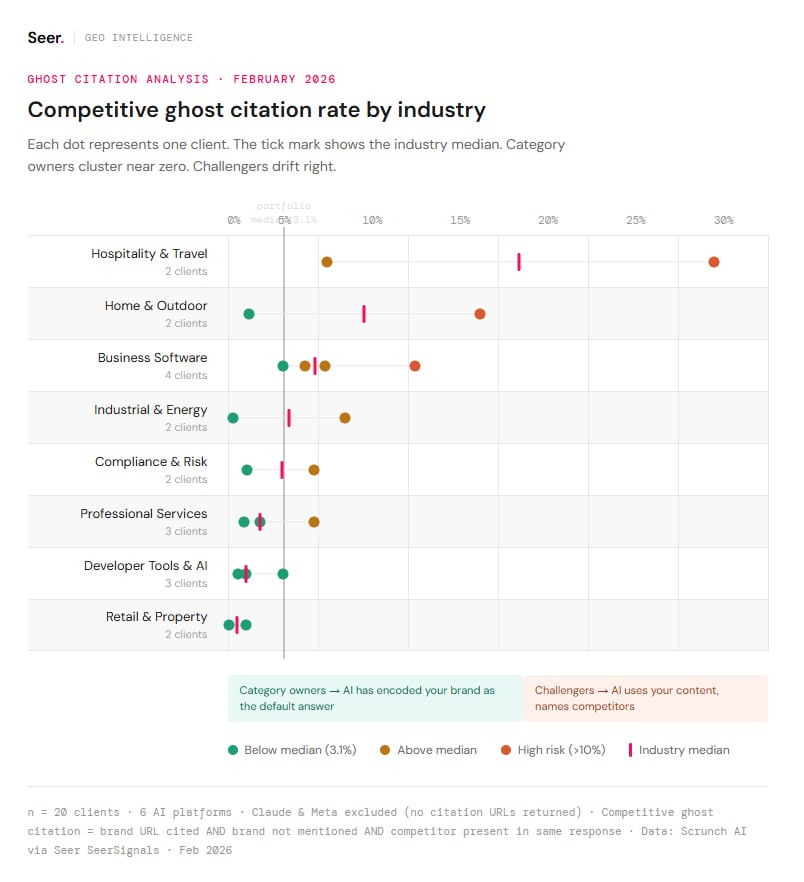
Частота призрачных цитаций (когда источник указан, а бренд нет) сильно скачет по нишам.
В Hospitality & Travel разрыв между лидерами и аутсайдерами превышает 20 процентных пунктов — хотя обе стороны представляют крупные бренды.
Ключевой фактор: сила сигнала сущности бренда в Графе Знаний ИИ.
Лидеры категорий (те, чье имя стало синонимом ниши в сети) сводят призрачные цитации практически к нулю.
Industrial Services выдает 0.3%; Financial Services и HR Technology — ниже 2%.
Все эти компании достигли такого статуса через годы прокачки бренда еще до появления ИИ.
Максимальный урон прилетает на этапе Awareness: конкурентная частота призрачных цитаций составляет 5.0%.
Осведомительные промпты формируют восприятие категории у покупателей, которые еще не слышали ни о тебе, ни о твоих конкурентах.
Твой контент формирует этот диалог.
Твое имя в нем не фигурирует.
Слой 1: Делай имя бренда грамматическим подлежащим в инсайтах, которые извлекает ИИ. Не "пять подходов к комплаенс-обучению", а "В [Бренд] наш подход к комплаенсу начинается с…". Извлечь этот текст без твоего имени становится невозможно. Слой 2: Строй сигналы графа сущностей, которые ИИ считывает при выборе бренда — записи в Wikidata, присутствие в Wikipedia, микроразметка Organization с тегом sameAs, единое каноническое имя бренда на всех ресурсах, микроразметка автора, связывающая экспертов с компанией, FAQ-разметка с именем бренда в ответах. Маленькие конкуренты с чистыми графами сущностей выносят здесь крупных игроков. Слой 3: Получай упоминания бренда на сторонних площадках именно в контексте рекомендаций — в отчетах аналитиков, пресс-релизах, агрегаторах отзывов, на партнерских страницах. Упоминание канонического имени бренда в H1 на страницах Gartner или TechCrunch учит модель, что твое имя должно всплывать, когда юзер спрашивает про категорию.
Трекай показатель Competitive Ghost Citation Rate ежемесячно с разбивкой по платформам и этапам воронки.
Если график идет вниз — прокачка сущности работает.
Если ползет вверх — инвестиции в контент обгоняют вложения в бренд, и разрыв растет.
Ни одно из этих действий не дает результатов за ночь; модели переиндексируют данные по собственному графику.
Закладывай от нескольких недель до месяцев до появления измеримой динамики.
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
– https://t.me/MikeBlazerX
– https://t.me/tribute/app?startapp=sE4X
Источник новости https://t.me/mikeblazerx/6342...
ТОП-10 каналов по SEO ![]()
Последние интересные посты
