
 Как ChatGPT Search выбирает источники для краулинга?
Как ChatGPT Search выбирает источники для краулинга?
 135
135
Как ChatGPT Search выбирает источники для краулинга?
Тайтл и дескрипшен по-прежнему важны!
Последние пару месяцев я задавал вопросы команде поддержки ChatGPT, пытаясь разобраться в процессе работы ChatGPT Search, — пишет Жером Саломон.
Вчера я узнал кое-что новое :)
Я уже знал, что когда вы отправляете промпт с активированной функцией Поиска:
1) ChatGPT преобразует промпт в один или несколько поисковых запросов к Bing
2) Bing возвращает список результатов поиска
3) Бот ChatGPT-user краулит подборку релевантных источников
4) ChatGPT включает релевантный контент в ответ со встроенными ссылками на источники
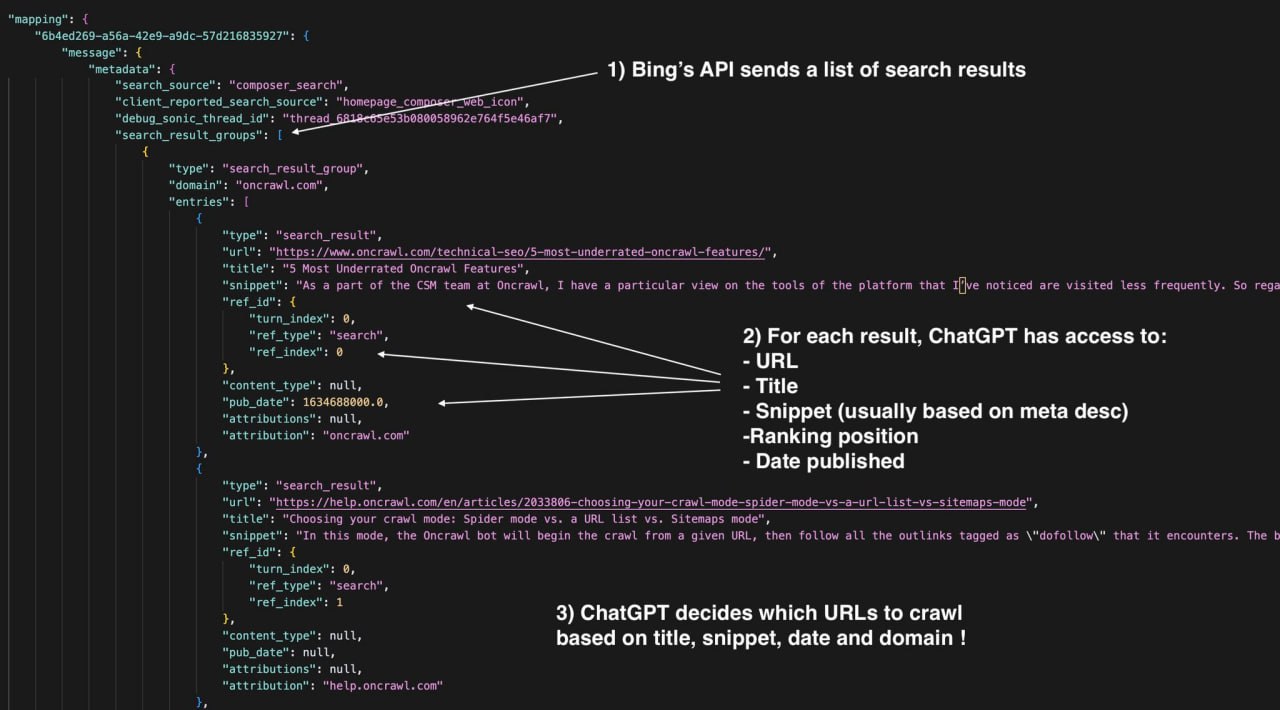
При изучении JSON-файла с диалогом ChatGPT можно увидеть полный список результатов поиска (включая те, которые ChatGPT не использовал в ответе).
Для каждого результата вы получаете:
— URL
— Тайтл
— Сниппет (обычно на основе мета-дескрипшена)
— Позицию в выдаче
— Метаданные (например, дата публикации)
Отвечая пользователю, ChatGPT должен в реальном времени выбрать и прокраулить несколько источников, чтобы дать наилучший ответ.
Мне было интересно, как эти URL выбираются из длинного списка результатов поиска.
Поэтому я снова спросил у команды поддержки :)
Вот их ответ:
"Решение о том, какие страницы краулить, в первую очередь зависит от релевантности тайтла, содержания сниппета, свежести информации и авторитета домена".
Тайтл и мета-дескрипшен играют важную роль.
Они помогают ChatGPT предположить, сможет ли ваша страница предоставить релевантный контент для ответа на промпт.
Практический совет для ваших тайтлов и мета-дескрипшенов:
— Будьте описательными, конкретными и точными
— Используйте ключевые термины, которые четко отражают содержание
— Отдавайте предпочтение ясности, а не кликбейту
Возвращаемся к основам
P.S. Как полуить JSON писалось тут.
@MikeBlazerX
– https://www.linkedin.com/feed/update/urn:li:activi...
– https://t.me/MikeBlazerX/5081
– https://t.me/MikeBlazerX
Источник новости https://t.me/mikeblazerx/5208...
ТОП-10 каналов по SEO ![]()
Последние интересные посты
