
 Семантическая Подсветка: Локальная лаба для симуляции Passage...
Семантическая Подсветка: Локальная лаба для симуляции Passage...
 188
188
Семантическая Подсветка: Локальная лаба для симуляции Passage Indexing
Мы одержимы "качественным контентом", но алгоритмы волнует только плотность сигнала.
Zilliz выкатили опен-сорс модель, которая дает редкую возможность увидеть текст точно так, как его видит поисковый движок (retrieval engine).
Для SEO-спеца это, по сути, автономный симулятор "Passage Indexing".
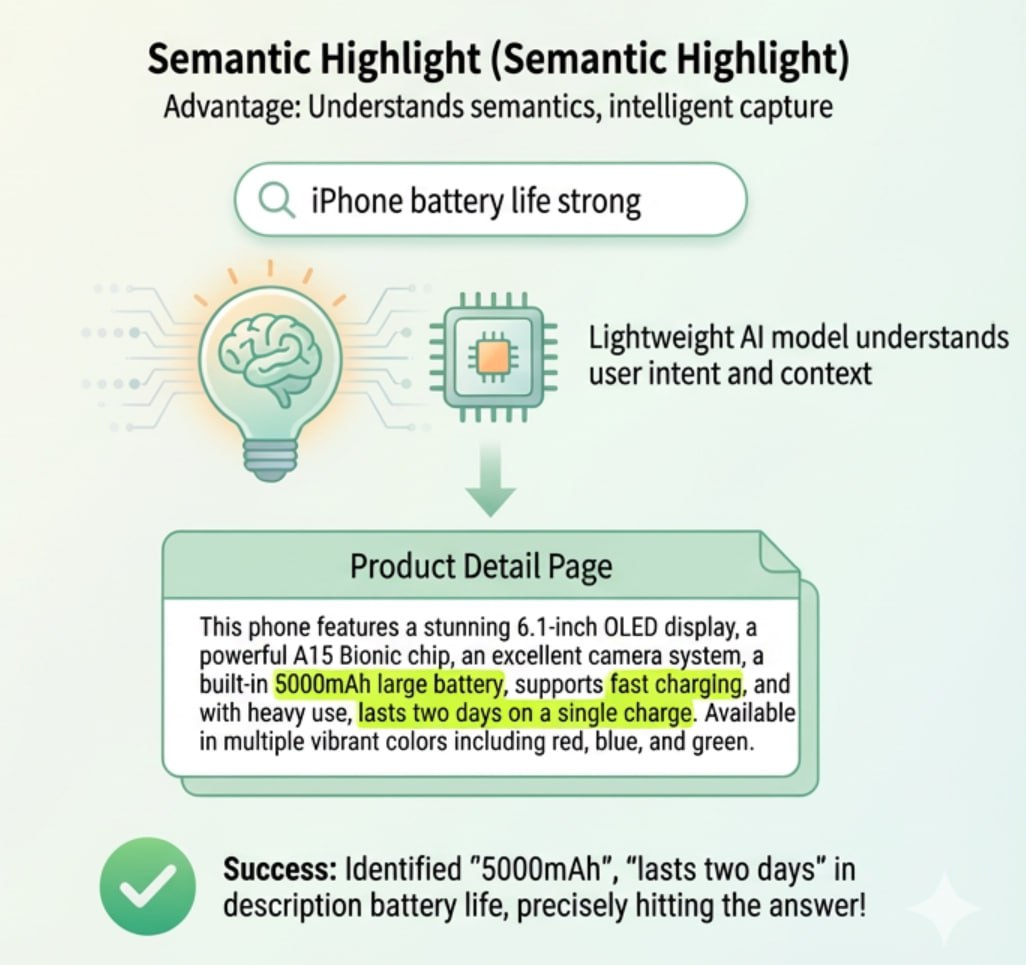
Модель решает конкретную проблему: "Semantic Highlighting" (Семантическая Подсветка).
Вместо суммаризации документа (которая часто галлюцинирует) или матчинга ключей (который фейлит на интенте), она скорит каждое предложение в тексте на основе его семантического вклада в конкретный запрос.
Она находит ту самую иголку в стоге сена, которая отвечает интенту юзера, отсекая шелуху вокруг.
В отличие от предыдущих моделей с потолком в 512 токенов, эта построена на `BGE`-`M3 Reranker v2` с окном контекста в 8192 токена.
Вы можете скормить ей лонгрид на 5000 слов и целевой ключ, и она изолирует конкретные предложения, которые несут семантический вес.
Если ваш таргет-ключ подсвечивает предложения, которые фактически нерелевантны (дистракторы), вы сразу видите, почему не ранжируетесь.
Разрабы продемонстрировали эту точность тестом "Сценарист против Драматурга".
На вопрос "Кто написал Убийство священного оленя"?, модели на основе ключей отвлекались на упоминание "Еврипида" (автора оригинальной пьесы) позже в тексте.
Эта модель корректно определила реальных сценаристов фильма в первом абзаце, потому что она распарсила семантический интент "film writer" против "source material".
Прямые применения в SEO:
— Оптимизация Сниппетов: Прогоните свой контент через модель против целевых запросов. Если модель хайлайтит дистрактор вместо вашего задуманного ответа, ваш семантический сигнал размыт.
— Чистый Инпут для `AI`-стеков: Перед тем как скормить спаршенный контент в LLM для программного рерайта, используйте это, чтобы извлечь только семантическое ядро. Вы срежете входные токены на 70-80%, эффективно повышая соотношение сигнал/шум ваших страниц.
— Отладка Ретривала: Если страница ранжируется по неверному интенту, этот механизм подсветки может выявить, какие конкретно предложения триггерят ложноположительный результат.
Модель достигает такой точности, потому что была обучена на 5 миллионах билингвальных сэмплов, сгенерированных с Reasoning Traces (Chain of Thought).
Они заставили модель-учителя (Qwen3) выдавать процесс <think> перед разметкой данных, радикально снижая количество "ленивых" аннотаций, обычных для синтетических датасетов.
Это Encoder-only модель (0.6B параметров), фактически загружаемый актив, который позволяет вам проводить аудит релевантности контента с математической точностью, а не гадать, что может понравиться Гуглу.
Модель можно крутить локально!
Скачать модель: https://huggingface.co/zilliz/semantic-highlight-bilingual-v1
https://huggingface.co/blog/zilliz/zilliz-semantic-highlight-model
@MikeBlazerX
Закрытый канал: @MikeBlazerPRO
– https://t.me/MikeBlazerX
– https://t.me/tribute/app?startapp=sE4X
Источник новости https://t.me/mikeblazerx/6141...
ТОП-10 каналов по SEO ![]()
Последние интересные посты
