
 Просматривая некоторые проиндексированные страницы клиента...
Просматривая некоторые проиндексированные страницы клиента...
 598
598
Просматривая некоторые проиндексированные страницы клиента, Оливер Мейсон заметил, что основной контент не всегда присутствует в отрендеренном DOM, возвращаемом инструментом инспекции URL.
Хотя в Google Search Console можно получить информацию о файлах, которые Гугл не загрузил (только для проиндексированных страниц), мы все же можем сделать обоснованный вывод, что отсутствие основного содержимого, скорее всего, является основной причиной того, что представленные URL были просканированы, но не проиндексированы
Большинство SEO-специалистов знакомы с отключением JavaScript, чтобы посмотреть, как будет выглядеть страница без него.
Еще вы наверное слышали о том, что у Гугла есть бюджет на рендеринг и Гугл в процессе рендеринга не всегда скачивает все шрифты и джаваскрипт файлы используемые на страницах.
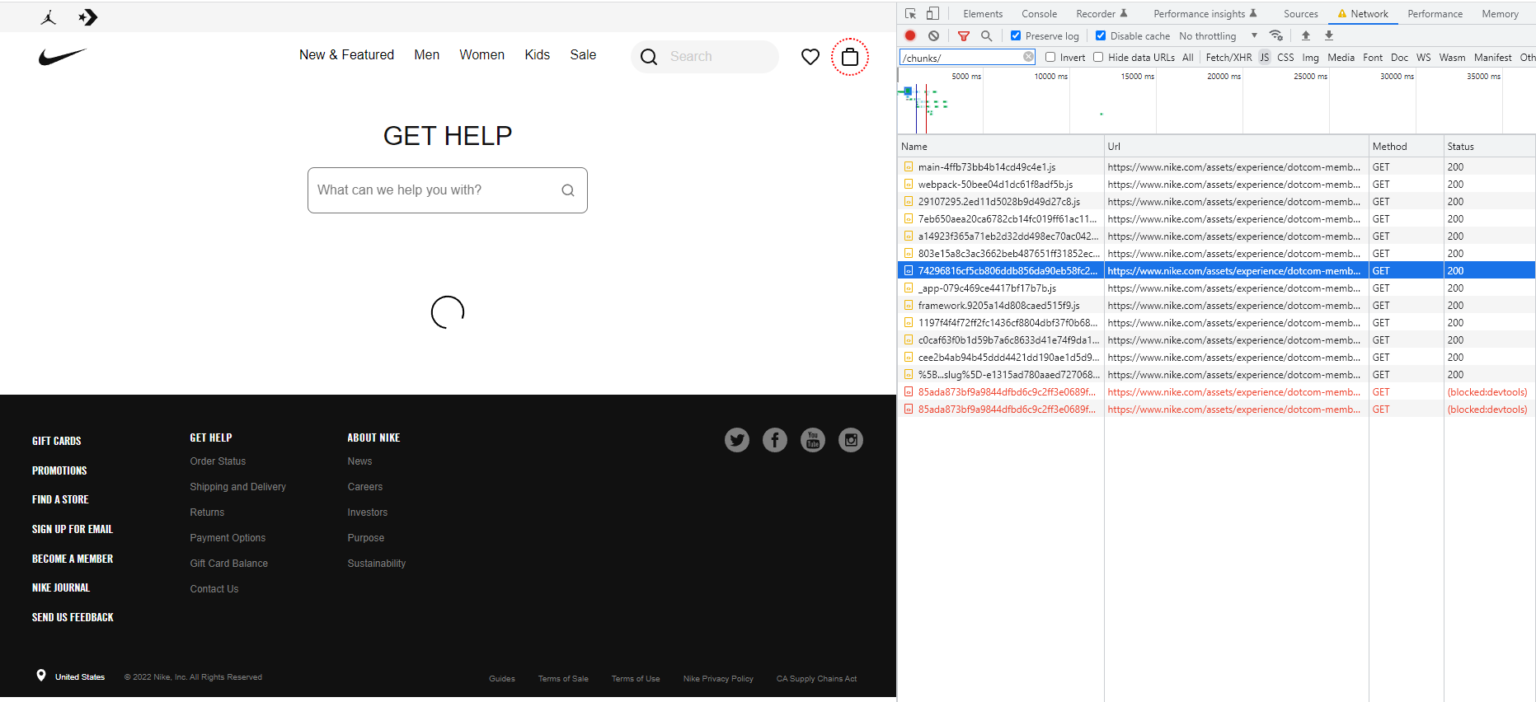
На примере страницы nike.com/help/a/shipping-delivery Оливер показал, как отключение всего одного JS файла сделает отображение основного контента на странице НЕВОЗМОЖНЫМ.
Теперь представьте, как Гугл экономя ресурсы может решить не скачивать этот JS файл...
У Найка есть 1 файл, без которого ничего не работает, а на сайте клиента Оливера таких "блокировщиков" - 25!
Пример Nike иллюстрирует, что существуют сценарии, в которых мы не просто просим Google выполнить некоторые JS, чтобы добраться до основного контента, но требуем, чтобы они загрузили и выполнили 25, 50, 100+ отдельных скриптов, чтобы увидеть основной контент на одном URL.
Рассчитывать на то, что Гугл это сделают, очень оптимистично.
Более подробно обо всем этом Оливер рассказывает в статье, там также узнаете, как пользоваться фичей "Request Blocking" в Chrome Dev Tools.
@MikeBlazerX
– https://ohgm.co.uk/render-gauntlet-request-blockin...
– https://t.me/MikeBlazerX
Источник новости https://t.me/mikeblazerx/561...
ТОП-10 каналов по SEO ![]()
Последние интересные посты
