
 Твоя навигация может съедать лимиты LLM на чтение ⁉️
Твоя навигация может съедать лимиты LLM на чтение ⁉️
 96
96
Твоя навигация может съедать лимиты LLM на чтение ⁉️
Мы внимательно изучили, как именно ChatGPT Deep Research читает страницы, чтобы понять, что на самом деле происходит под капотом, раскрывает Давид Конитцни.
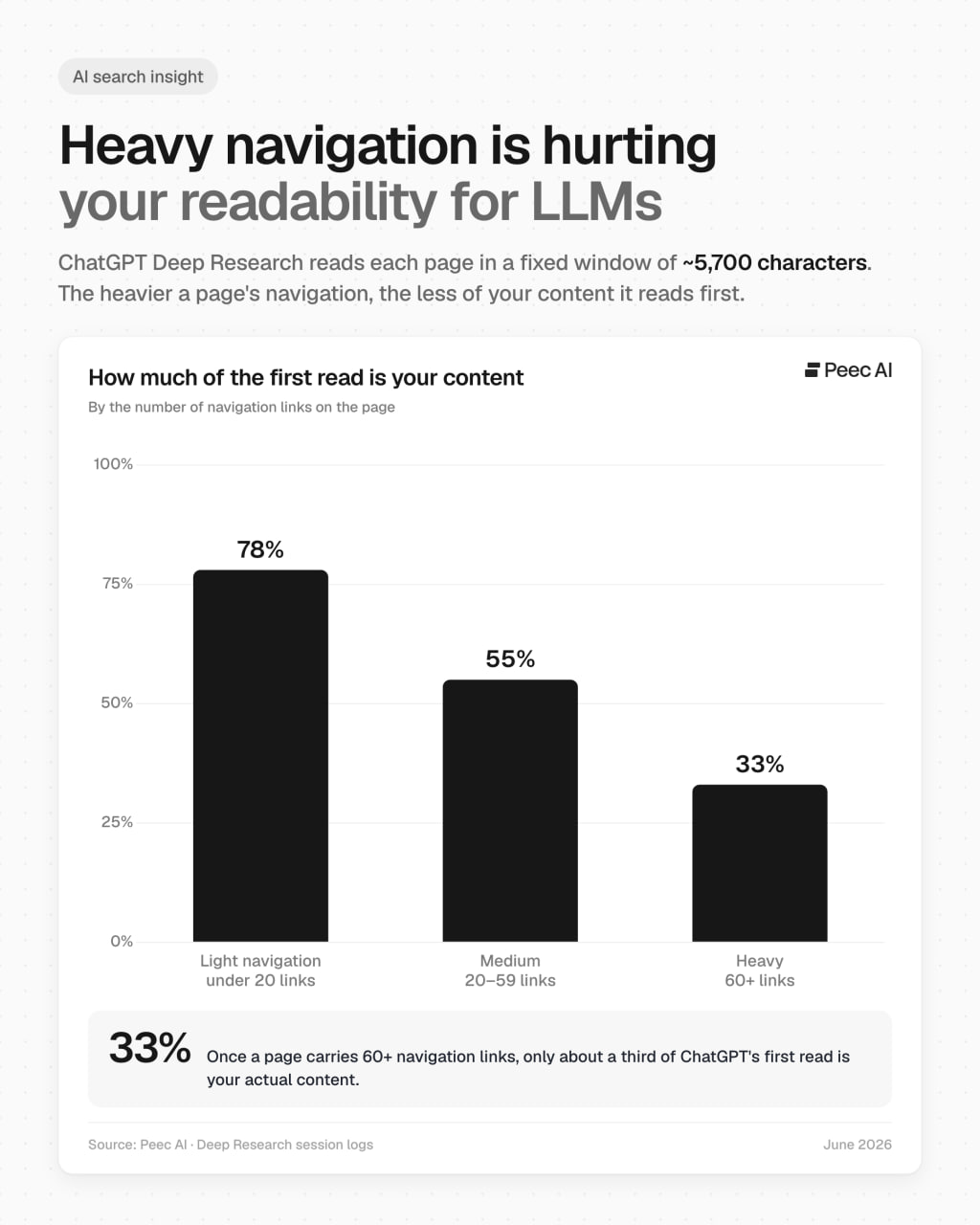
При первом заходе Deep Research читает каждую страницу через фиксированное окно примерно в 5 700 символов.
Чем тяжелее навигация на странице, тем меньше этого бюджета остается на твой контент.
Мы сгруппировали страницы по количеству навигационных ссылок:
➡️ Легкая навигация (менее 20 ссылок) Около 78% первого чтения — это твой фактический контент.
Так выглядит чистая страница, где контент на первом месте.
➡️ Средняя (20–59 ссылок) Около 55%.
Почти половина лимита уходит на навигацию и разметку, и сюда попадает большинство страниц.
➡️ Тяжелая навигация (60+ ссылок) Всего около 33%.
Две трети чтения уходит на ссылки еще до того, как модель доберется до твоего ответа.
Так что на перегруженных сайтах больше половины бюджета на чтение улетает еще до того, как начнется твой реальный контент.
Инсайты комьюнити
— Deep Research парсит сырой HTML страницы, а не отрендеренный в браузере текст — он отслеживает урлы, анкоры, альты и другие элементы через WebSocket во время запроса. Навигационная разметка напрямую конкурирует с контентом внутри фиксированного окна чтения.
— Полевые наблюдения: Deep Research не ищет и не кликает по файлам .md, даже если на них есть внутренняя перелинковка, поэтому отдача Markdown-версий без стилей пока не помогает парсить с большей экономией токенов в этом агенте.
@MikeBlazerX
⚠️ Закрытый канал: @MikeBlazerPRO
– https://x.com/DavidKonitzny/status/206461912767568...
– https://t.me/MikeBlazerX
– https://t.me/tribute/app?startapp=sE4X
Источник новости https://t.me/mikeblazerx/6498...
ТОП-10 каналов по SEO ![]()
Последние интересные посты
