
 Пиар-ловушка Google: Почему векторная математика опровергает...
Пиар-ловушка Google: Почему векторная математика опровергает...
 186
186
Пиар-ловушка Google: Почему векторная математика опровергает "Не делайте чанкинг"
Google активно дезинформирует SEO-специалистов о том, как функционируют их собственные системы.
Дэнни Салливан недавно публично не рекомендовал разбивать контент на "мелкие кусочки" (chunks) для LLM, утверждая, что креаторам не стоит создавать ничего специфического для Поиска.
Это ловушка.
Мы не слушаем заявления пиарщиков; мы смотрим на фундаментальную математику информационного поиска (Information Retrieval), которая доказывает, что "чанкинг" — это прямой эксплойт для видимости в RAG.
Поисковые движки и LLM работают на модели векторного пространства (Vector Space Model), где релевантность — это вычисляемая дистанция (обычно косинусное сходство) между вектором промпта юзера и вектором вашего контента.
В пайплайне RAG системы сравнивают пассажи бок о бок, чтобы определить, что скормить ИИ.
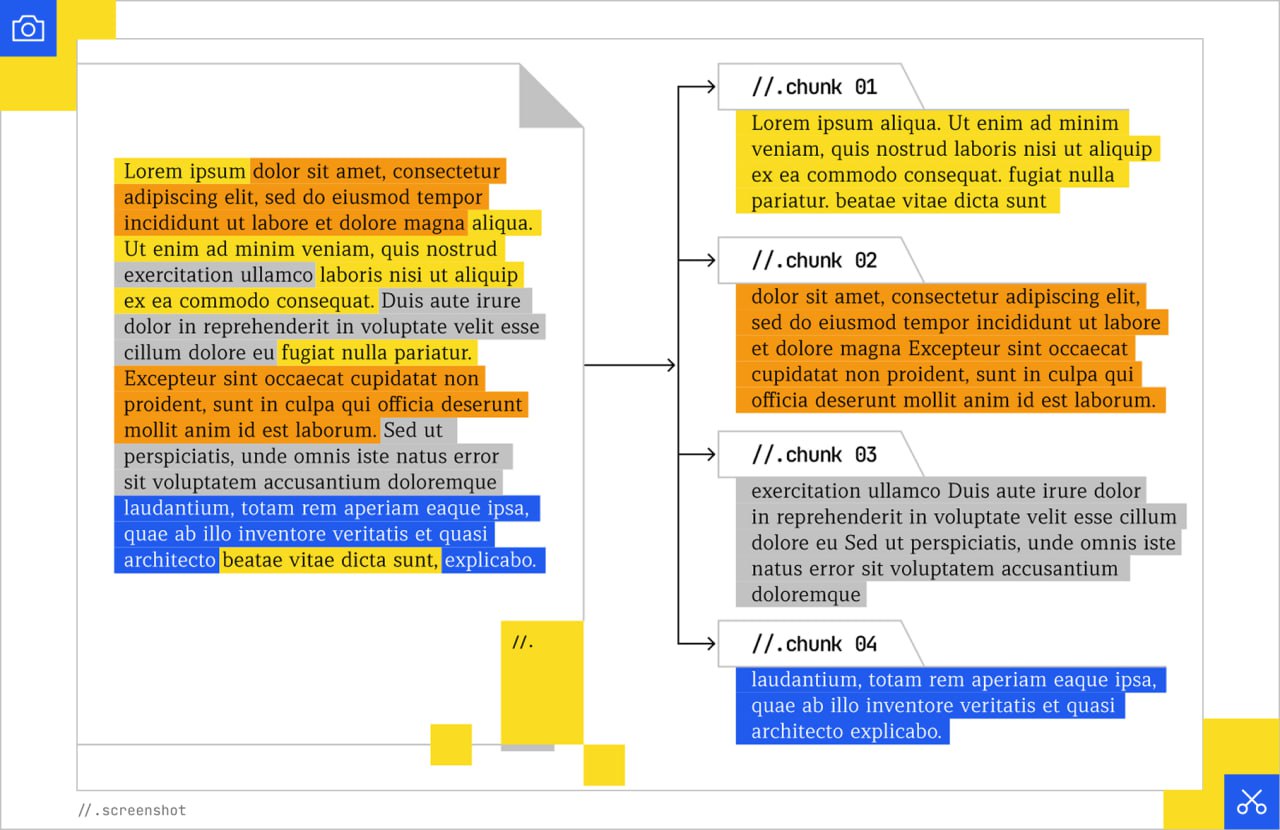
Длинный монолитный блок текста, покрывающий несколько тем, размывает свою векторную релевантность.
Более короткий, сфокусированный "чанк" создает более плотный и извлекаемый сигнал.
Майк Кинг доказал эту техническую реальность твердыми данными, используя свой тул BubbaChunk.
Он взял один параграф, таргетирующий две разные темы — [machine learning] и [data privacy] — и разбил его на два атомарных чанка, не меняя ни единого слова в тексте.
Результат был мгновенным: скор косинусного сходства для конкретного запроса подскочил на 19.24%.
Когда он добавил специфические заголовки к этим чанкам, чтобы заякорить вектор, релевантность взлетела еще на 17.54%.
Математика бинарна: конкретные чанки математически более релевантны, чем сумма их частей.
Это идеально мэтчится с существующей архитектурой Google.
Их "Passage Indexing" — это фактически Dense Retrieval, выполняющий поиск ближайшего соседа (Approximate Nearest Neighbor - ANN).
Это фундаментальная логика AI-поиска: если ваш контент не структурирован в дискретные, извлекаемые объекты, он невидим для слоя ретривала (retrieval layer).
Скептики утверждают, что расширение контекстных окон — как 1M токенов у Gemini — делает чанкинг устаревшим, потому что ИИ может просто "прочитать всю книгу".
Это игнорирует реальность стоимости инференса.
В вебе, сформированном под агентов, вычисления — это новый дефицит.
Новые архитектуры, такие как Infini-attention от Google и `Mixture of Recursions` (MoR) от DeepMind, опираются на "сжимаемую память" и переменную глубину обработки.
Они не читают линейно; они маршрутизируют токены на основе сложности.
Если ваш контент не является атомарной единицей смысла, он теряется при сжатии или отбрасывается как слишком дорогой для переваривания.
Мы уходим от веба "под Google", где вы пишете статьи для линейного чтения людьми.
В вебе "под Агентов" боты срывают переплет с книги и извлекают только конкретные пассажи, которые мэтчатся с вектором.
Вы должны перестать писать "контент" и начать строить `API` смыслов.
Форматируйте под программную читаемость или останетесь за бортом.
https://ipullrank.com/misinformation-about-chunking
@MikeBlazerX
Закрытый канал: @MikeBlazerPRO
– https://t.me/MikeBlazerX
– https://t.me/tribute/app?startapp=sE4X
Источник новости https://t.me/mikeblazerx/6131...
ТОП-10 каналов по SEO ![]()
Последние интересные посты
