
 Позиция в извлечении перевешивает авторитет домена для...
Позиция в извлечении перевешивает авторитет домена для...
 84
84
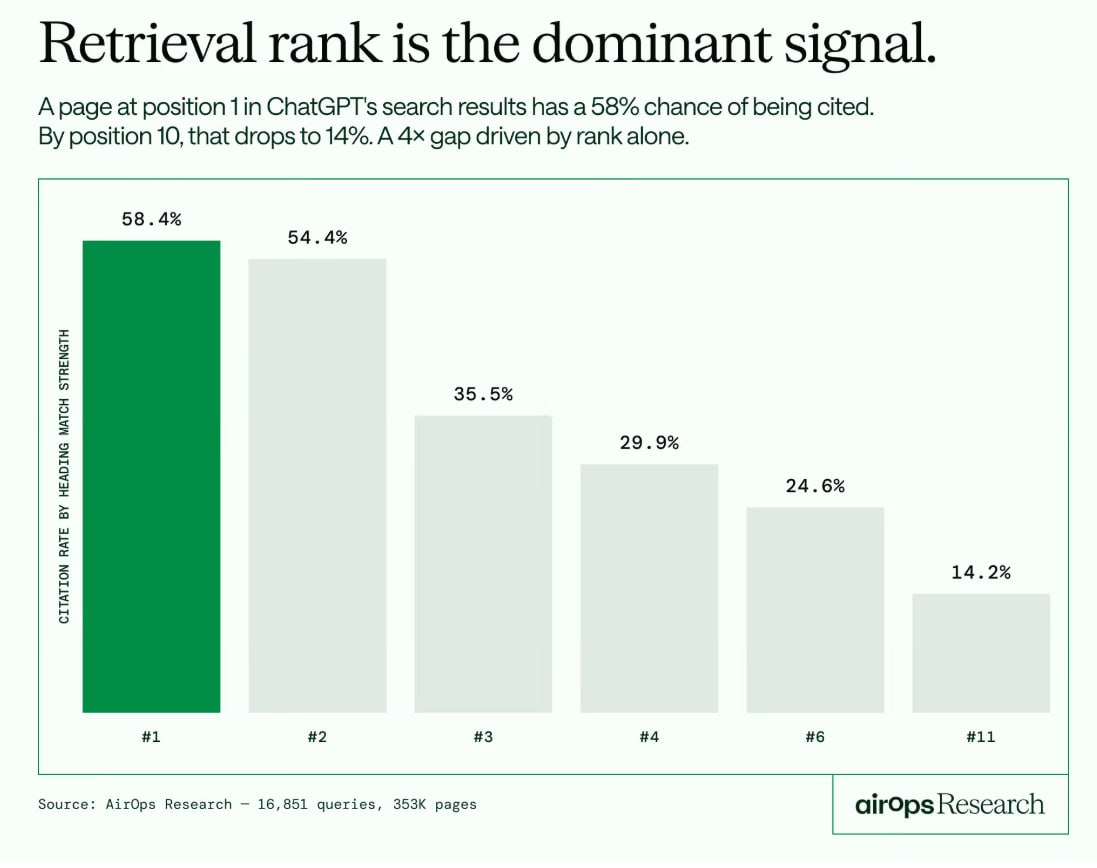
Позиция в извлечении перевешивает авторитет домена для цитирования в ChatGPT — разница в 4 раза
ChatGPT плевать на твой авторитет домена или бэклинки.
Проанализировав 16 851 уникальный запрос, 50 553 сессий ChatGPT и 353 799 страниц, AirOps выявил железобетонный паттерн: позиция в извлечении — единственный сигнал, который стабильно предсказывает, получит ли страница цитату.
Страницы на нулевой позиции в результатах поиска ChatGPT цитируются в 58% случаев.
На десятой позиции — 14%.
Этот четырехкратный разрыв сохраняется при любых контрольных проверках.
Страница с посредственной релевантностью на нулевой позиции (частота цитирования 56%) обходит сверхрелевантную страницу на шестой позиции и ниже (26%).
Извлечение решает всё; качество контента усиливает сигнал, но не может компенсировать слабую находимость.
Траст домена и ссылочное показывают нулевую корреляцию с цитированием, причем наблюдается даже легкая обратная зависимость.
У страниц, которые цитируются всегда, средний DA был ниже (53), чем у тех, которые не цитируются никогда (56).
Авторитет сайта вообще ничего не значит: YouTube (DA 100) получает 2.4% цитируемости, тогда как Wikipedia (DA 95) собирает 59.2%.
ChatGPT оценивает конкретные страницы, а не домены.
Внутри окна извлечения доминирует совпадение с запросом.
Страницы, чьи заголовки плотно закрывают исходный запрос, получают цитату в 41% случаев; при слабом совпадении показатель падает до 30%.
Даже с поправкой на ранжирование, точное вхождение добавляет +19 процентных пунктов к шансу на цитирование.
Узкофокусные страницы рвут масштабные гайды: те, что закрывают 26–50% подтем ChatGPT при fan-out поиске, отрабатывают лучше страниц, покрывающих 100%.
Исчерпывающий охват сигнализирует о поверхностном подходе "обо всем понемногу"; умеренный охват в связке с мощной первичной релевантностью доказывает глубину.
Структура контента помогает цитируемости, но не драйвит ее.
Объем текста достигает пика на отметке 500–2 000 слов (34.3% цитирований); страницы свыше 5 000 слов проседают до 28.6%.
Микроразметка накидывает +6.5 п.п.
(лучше всего тащат FAQPage, MedicalWebPage, BreadcrumbList).
Заголовки: 4–10 подзаголовков для статей — это оптимум (33.2%); 1–3 заголовка не дотягивают (28%).
Это базовый минимум.
Свежесть усиливает релевантные страницы.
Контент возрастом 30–89 дней выдает максимальные 32.8% цитируемости.
Очень свежие материалы (< 30 дней) проседают до 25.3% — скорее всего, из-за неполной индексации.
Страницы старше двух лет скатываются к 27.5%.
Бонус за свежесть (+4.2 п.п.) работает только для страниц с мощным совпадением по запросу; на страницах со слабой релевантностью эффект возраста стремится к нулю.
Чтобы забирать цитаты в ChatGPT, оптимизируй извлечение в первую очередь.
Убедись, что контент легко найти, заголовки матчатся с запросом, а структура вычищена.
Траст домена и ссылочная масса остаются Гуглу — ChatGPT оценивает тебя по ценности конкретной страницы и ее доступности для извлечения.
https://www.airops.com/report/the-fan-out-effect-what-happens-between-a-query-and-a-citation
@MikeBlazerX
⚠️ Закрытый канал: @MikeBlazerPRO
– https://t.me/MikeBlazerX
– https://t.me/tribute/app?startapp=sE4X
Источник новости https://t.me/mikeblazerx/6412...
ТОП-10 каналов по SEO ![]()
Последние интересные посты
