
 Как структура контента влияет на AI-поиск
Как структура контента влияет на AI-поиск
 147
147
Как структура контента влияет на AI-поиск
Форензик-анализ показывает, что "письмо для AI" — это меньше про качество и больше про эксплуатацию поиска векторов (vector-search retrieval).
Контролируемый тест против эмбеддингов Google Vertex AI обнаружил, что форматирование Q&A стабильно дает самые высокие показатели семантической релевантности, манипулируя слоем извлечения (retrieval layer) в RAG.
Механизм: системы чанкают (нарезают) текст, эмбеддят чанки в вектора, хранят их в индексе HNSW, затем извлекают чанки с самой высокой косинусной близостью (cosine similarity) к вектору запроса.
Провал Прозы
Плотная проза размывает сигнал по чанкам; когда ответ размазан по абзацам, сходство падает и вероятность извлечения снижается.
Эксплойт Q&A
Q&A — это контейнирование: поместите целевой ключ (Вопрос) и ответ (Ответ) рядом, чтобы они попали в один чанк, концентрируя семантический сигнал и форсируя более высокий скор совпадения по сравнению с нарративной прозой.
Данные Теста и Иерархия
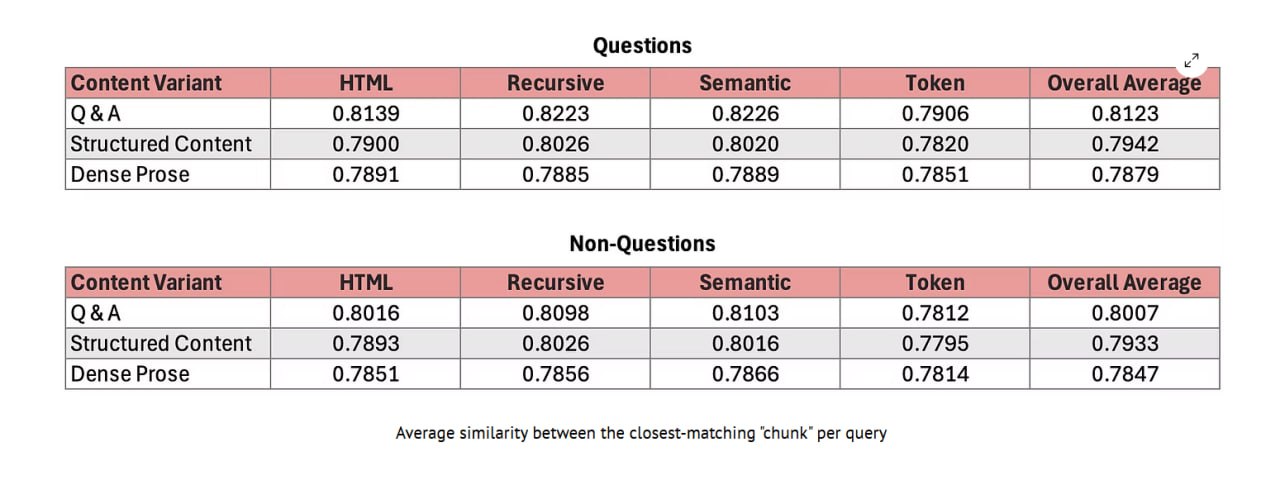
3 стиля (Плотная Проза, Структурированный Контент, Q&A) × 4 чанкера: Токен-бейзд, Рекурсивный (LangChain), HTML-aware, Семантический (AI-driven).
Иерархия сохранилась в каждом сценарии:
1. Q&A: Высочайшая релевантность в 100% тестов; "универсальный ключ", который обходит неопределенность неизвестного чанкинга.
2. Структурированный: <h2> + <li> может соперничать с Q&A на запросах без вопросов, но никогда не бьет пик.
3. Плотная Проза: Худший вариант; отсутствие разметки означает произвольные нарезки токенов, которые отсекают запрос от ответа.
Стратегический Протокол
Мы не видим точную логику чанкинга Google, но данные говорят, что у Q&A лучшие шансы на выживание через любой чанкер.
Чтобы вооружить это для жирных ключей:
— Форсируйте Чанк: <Heading>Question?</Heading> затем немедленно <p>Direct Answer.</p>.
— Структурный фоллбэк: Если Q&A невозможен, юзайте жесткую иерархию HTML, чтобы определить границы для HTML-aware парсеров.
Примечание: Это тестирует векторное сходство (извлечение), а не финальное ранжирование/генерацию.
Без извлечения нет ранжирования.
https://www.chris-green.net/post/content-structure-for-ai-search
@MikeBlazerX
🚷 Закрытый канал: @MikeBlazerPRO
– https://t.me/MikeBlazerX
– https://t.me/tribute/app?startapp=sE4X
Источник новости https://t.me/mikeblazerx/6202...
ТОП-10 каналов по SEO ![]()
Последние интересные посты
