
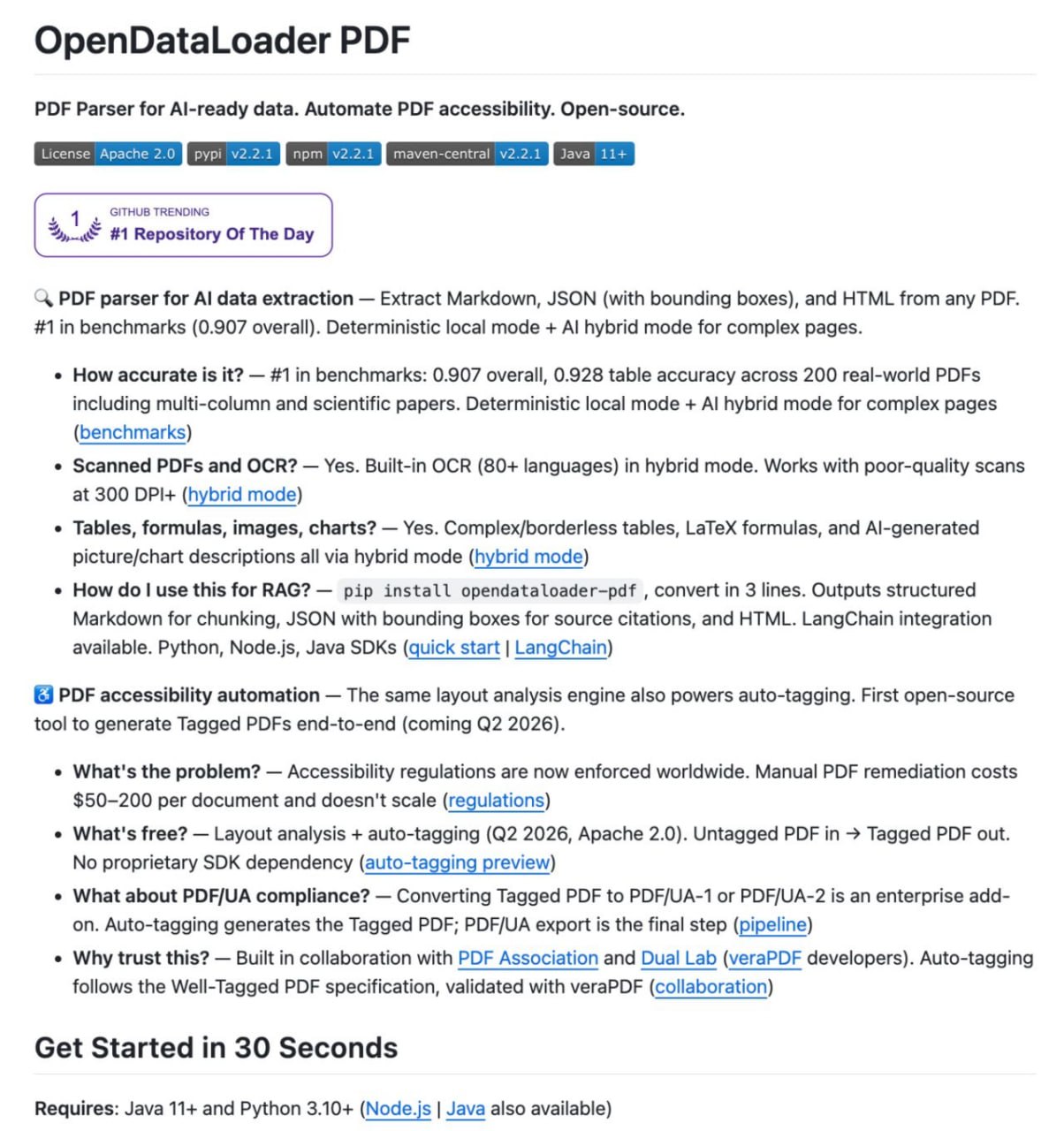
 🚨 Извлечение данных из PDF теперь решено
🚨 Извлечение данных из PDF теперь решено
 6
6 🚨 Извлечение данных из PDF теперь решено.
Кто-то выкатил в опенсорс тулзу, которая перегоняет PDF в Markdown на скорости 100 страниц в секунду 🤯
Называется OpenDataLoader.
Идеально пашет на CPU и декодирует таблицы, сложную верстку и вложенные структуры как абсолютный профи.
Самое крутое?
100% бесплатно и опенсорс.
Линк на репозиторий → https://github.com/opendataloader-project/opendataloader-pdf
Не забудьте влепить ⭐️, чтобы поднять видимость!
Инсайты комьюнити
— Тулзы для конвертации PDF в Markdown существуют уже 5+ лет (MarkItDown, pdfplumber) — но текущие решения всё ещё сыпятся на таблицах, подписях, уравнениях LaTeX, научных статьях и сложной верстке; ограничения для продакшена остаются нерешенными, несмотря на заявления о победе над извлечением.
@MikeBlazerX
⚠️ Закрытый канал: @MikeBlazerPRO
– https://www.linkedin.com/posts/charlywargnier_extr...
– https://t.me/MikeBlazerX
– https://t.me/tribute/app?startapp=sE4X
Источник новости https://t.me/mikeblazerx/6440...
ТОП-10 каналов по SEO ![]()
Последние интересные посты
