
 Google преобразует PDF в HTML для индексации (+ обнаруживает...
Google преобразует PDF в HTML для индексации (+ обнаруживает...
 690
690
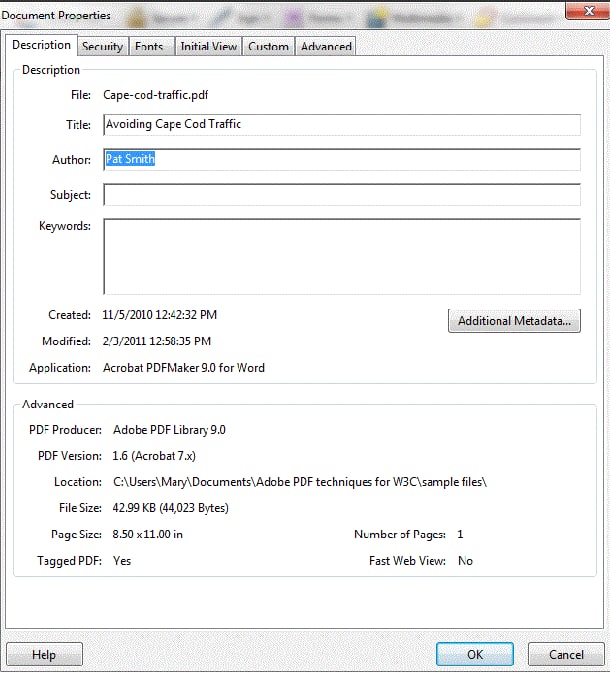
Google преобразует PDF в HTML для индексации (+ обнаруживает ссылки/якоря). Он берет заголовок документа и используют его в качестве элемента <title> в HTML. Несмотря на большинство руководств по SEO, тема (subject) не используется для мета-описания, Гугл не присваивает заголовки тегированному тексту PDF и не видит alt-текст.
Об этом Джон Мюллер писал еще в 2018 году.
Гугл добавляет номера страниц в HTML. Он распознает изображения, но только в том случае, если PDF является чистым изображением, а не сочетанием текста и изображений.
Источник
Довольно бесполезный/забавный факт - хотя Bing не использует мета киворды при ранжировании, он анализирует ключевые слова свойств PDF-файла в HTML-таблице и использует их при ранжировании - наряду с названием, автором, темой и датой создания.
@MikeBlazerX
– https://twitter.com/JohnMu/status/1035077656625250...
– https://twitter.com/screamingfrog/status/157539452...
– https://twitter.com/screamingfrog/status/157512906...
– https://t.me/MikeBlazerX
Источник новости https://t.me/mikeblazerx/602...
ТОП-10 каналов по SEO ![]()
Последние интересные посты
