
 В комментах попросили поделиться, как формировалась векторная БД...
В комментах попросили поделиться, как формировалась векторная БД...
 112
112 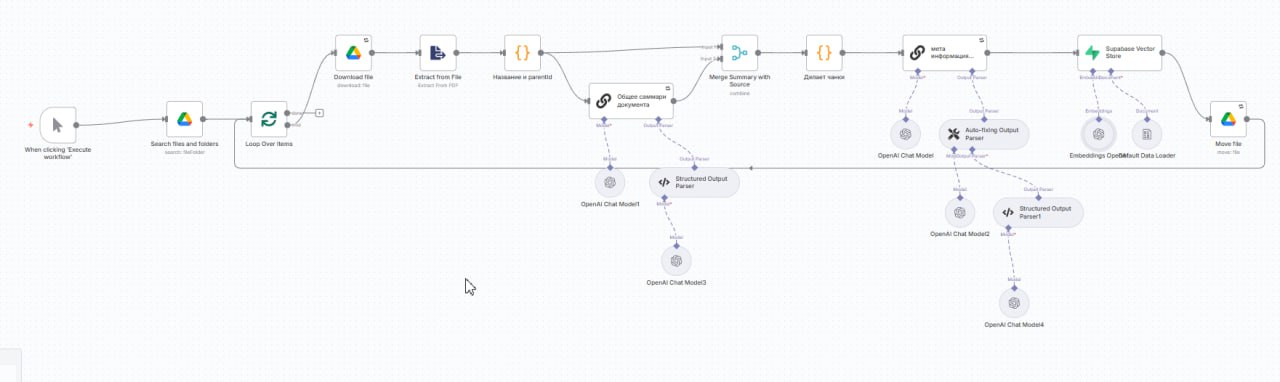
В комментах попросили поделиться, как формировалась векторная БД для агента на патентах.
Сразу сделаю важную оговорку. Какие-то проектики для себя, тесты, эксперименты я провожу в n8n. Клиентские проекты по автоматизации делаются на языках программирования и профессиональными разработчиками.
Как я записал патенты Google и подключил их к AI
1. Мы сделали агента, который берёт по одному файлу с Google Диска, где лежат патенты скопом.
2. Извлекает файл, нормализует текст.
3. Делается саммари всего документа с помощью AI, которое пойдёт в мета-информацию чанка.
4. Идёт нарезка документа на чанки по заданным нами правилам через свой код.
5. Подготовка мета-информации. ChatGPT готовит метаинформацию для каждого чанка:
✔️ ключевые термины из чанка;
✔️ ключевые термины SEO-применимости чанка типа линкбилдинг, schema, E-E-A-T.
Это нужно, чтобы сделать импровизированный граф знаний, чтобы чанки были связаны между собой ключами, и AI, которая будет работать уже с БД, могла раскрутить клубок информации.
Тут, конечно, можно сказать: а не проще ли перейти сразу на графовые БД? Нет, не проще. Когда ты уже руку набил на простые RAG, тебе проще быстро сделать RAG для себя. Графовые БД надо ещё освоить и набить шишки. А мне хотелось пощупать агента быстро.
6. Запись в векторную БД Supabase.
• Для эмбеддингов используется модель text-embedding-3-large.
• Все затраты у меня вышли в $10. Можно было сэкономить, но не хочется тратить час времени, чтобы сэкономить $2 на разовой задаче.
Ключевое и важное тут — это подготовка метаинформации и нарезка чанков, которая позволит модели лучше искать информацию.
Ключевые допущения — нет графической информации в чанках. Но это можно решить, но я не вижу повода так заморачиваться.
P.S. Публичный агент на патентах будет. Задача не в приоритете, но и не на паузе. Делается тихонько фоном.
Источник новости https://t.me/seokotenkov/612...
ТОП-10 каналов по SEO ![]()
Последние интересные посты
