
 Алгоритм обнаружения дубликатов Google сломался
Алгоритм обнаружения дубликатов Google сломался
 1149
1149
Алгоритм обнаружения дубликатов Google сломался
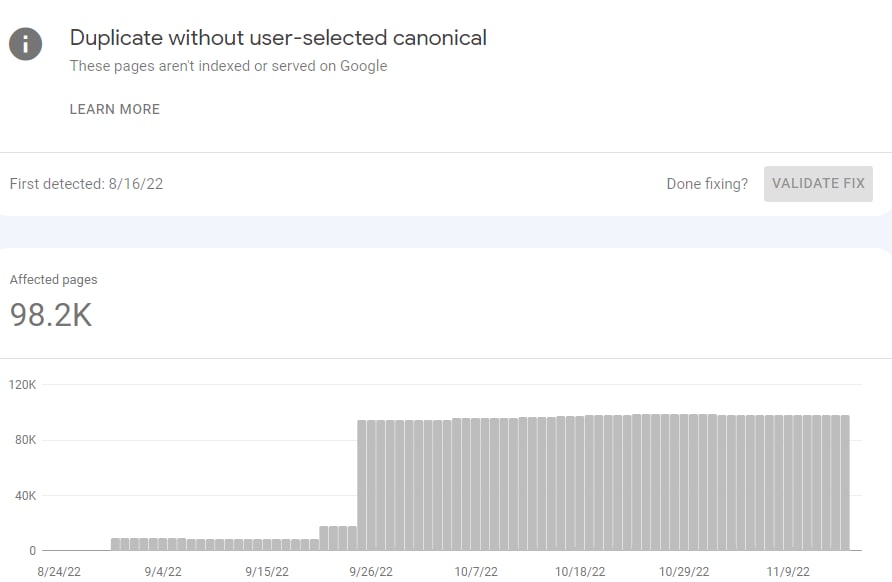
21 миллион страниц сайта были ошибочно помечены как дубликаты в течение прошлого месяца без каких-либо значительных структурных изменений со стороны клиента.
Теперь эти страницы не индексируются и не приносят трафик на сайт. А недоработки Google обходятся этому бизнесу в миллионы долларов.
Мы не знаем точно, какие алгоритмы использует Google для обнаружения дублированного контента, но многие из них оперируют общими фразами.
Например, на страницах категорий для мужчин и женщин есть футболки, спортивная одежда и джинсы. Но это не значит, что они являются дубликатами. Даже близко нет.
На данный момент вам следует помнить следующее:
— Google может деиндексировать URL-адреса на вашем сайте, считая их дубликатами, даже если это не так.
— Проверьте отчет об индексировании страниц в Google Search Console и посмотрите, не увеличилось ли количество URL-адресов, о которых сообщается как о "Дубликате, Google выбрал другой канонический, чем пользователь" или "Дубликате без выбранного пользователем канонического".
Ваши следующие шаги:
— Проверьте страницы, которые, по вашему мнению, важны для вашего бизнеса.
— Найдите примеры, когда Google выбирал неправильный canonical.
— Добавьте уникальный контент, чтобы Google увидел, что страница изменилась.
— Запросите индексацию в Google Search Console.
Больше подробностей в статье
@MikeBlazerX
– https://ziptie.dev/google-duplicate-detection-algo...
– https://t.me/MikeBlazerX
Источник новости https://t.me/mikeblazerx/849...
ТОП-10 каналов по SEO ![]()
Последние интересные посты
